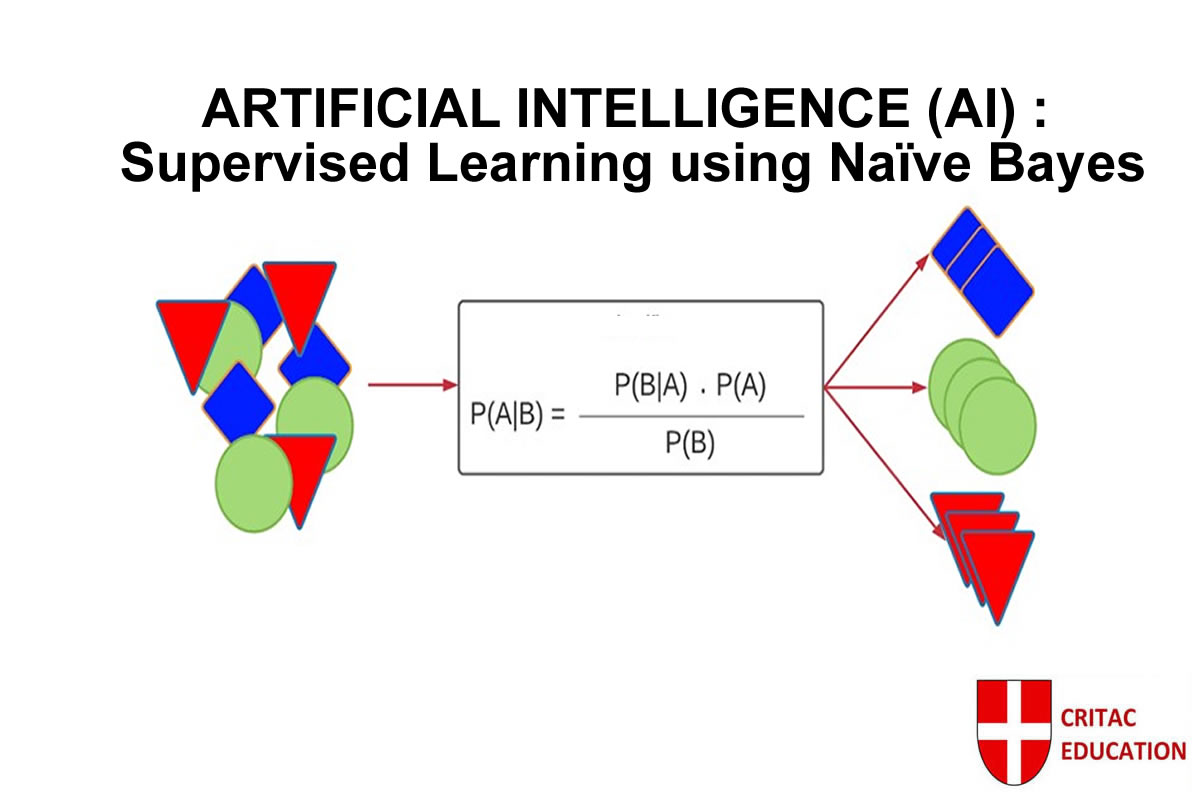
This course provides a rigorous and practical introduction to Supervised Learning using the Naïve Bayes algorithm, one of the most foundational probabilistic models in machine learning and artificial intelligence. Grounded in Bayes’ Theorem, the course explains how uncertainty, probability, and conditional independence are leveraged to make reliable predictions from labeled data.
Learners will explore the mathematical foundations of Naïve Bayes, including prior probabilities, likelihood estimation, posterior inference, and Laplace smoothing, with step-by-step numerical examples. The course emphasizes transparent model reasoning, making it ideal for understanding why a prediction is made, not just what the prediction is.
Practical applications are central to the course. Students will implement Naïve Bayes models for text classification tasks such as spam detection, document categorization, and sentiment analysis, using both manual probability computation and Python-based implementations. Attention is also given to feature extraction, model evaluation metrics (accuracy, precision, recall, F1-score, confusion matrix), and threshold tuning for decision-making in real-world systems.
Beyond implementation, the course situates Naïve Bayes within critical domains such as cybersecurity (phishing and spam detection), digital forensics, healthcare decision support, and intelligent information filtering, highlighting both its strengths and limitations. By the end of the course, learners will be able to design, train, evaluate, and critically assess Naïve Bayes classifiers in supervised learning contexts.